
We went through every U.S. collection in Ancestry’s catalog looking for large, person-level datasets from 1862 to 1950 with variables the decennial census doesn’t have. The census dropped its wealth questions in 1880 and never brought them back. It never recorded employer information. It provides snapshots only once a decade. And it captured almost nothing about the economic lives of formerly enslaved people.
Everything below is linkable to Census Tree by name, age, and location. But there’s an important practical distinction: some collections have their key variables in the searchable API index (easy to scrape at scale), while others index only names and put the interesting data on scanned page images (requires OCR).
The census dropped wealth questions in 1880. These are the best sources for individual-level income and property data in the decades that followed.
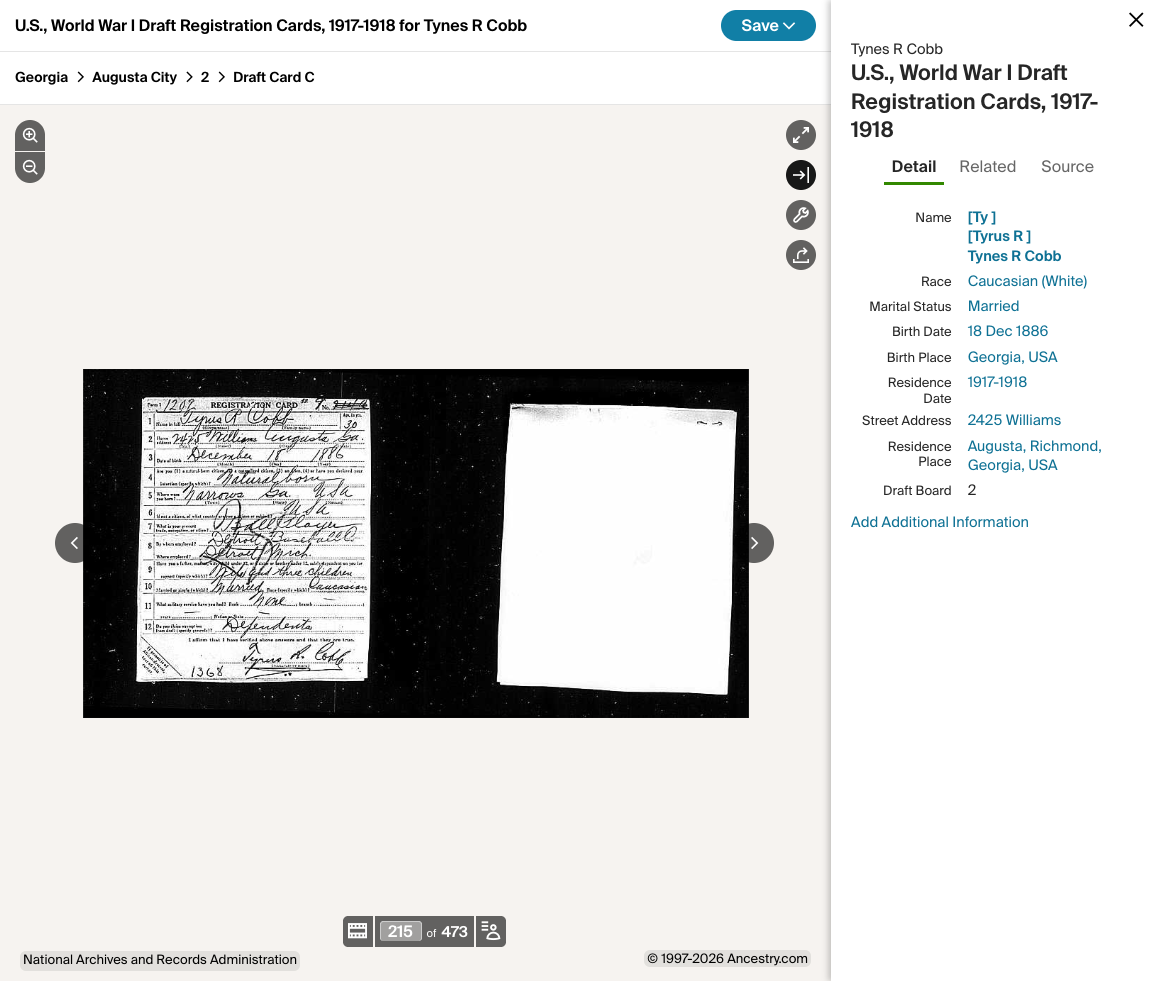
Near-universal male coverage with employer, race, and physical data the census never recorded. Combined, these cover essentially all adult men alive between 1917 and 1945.
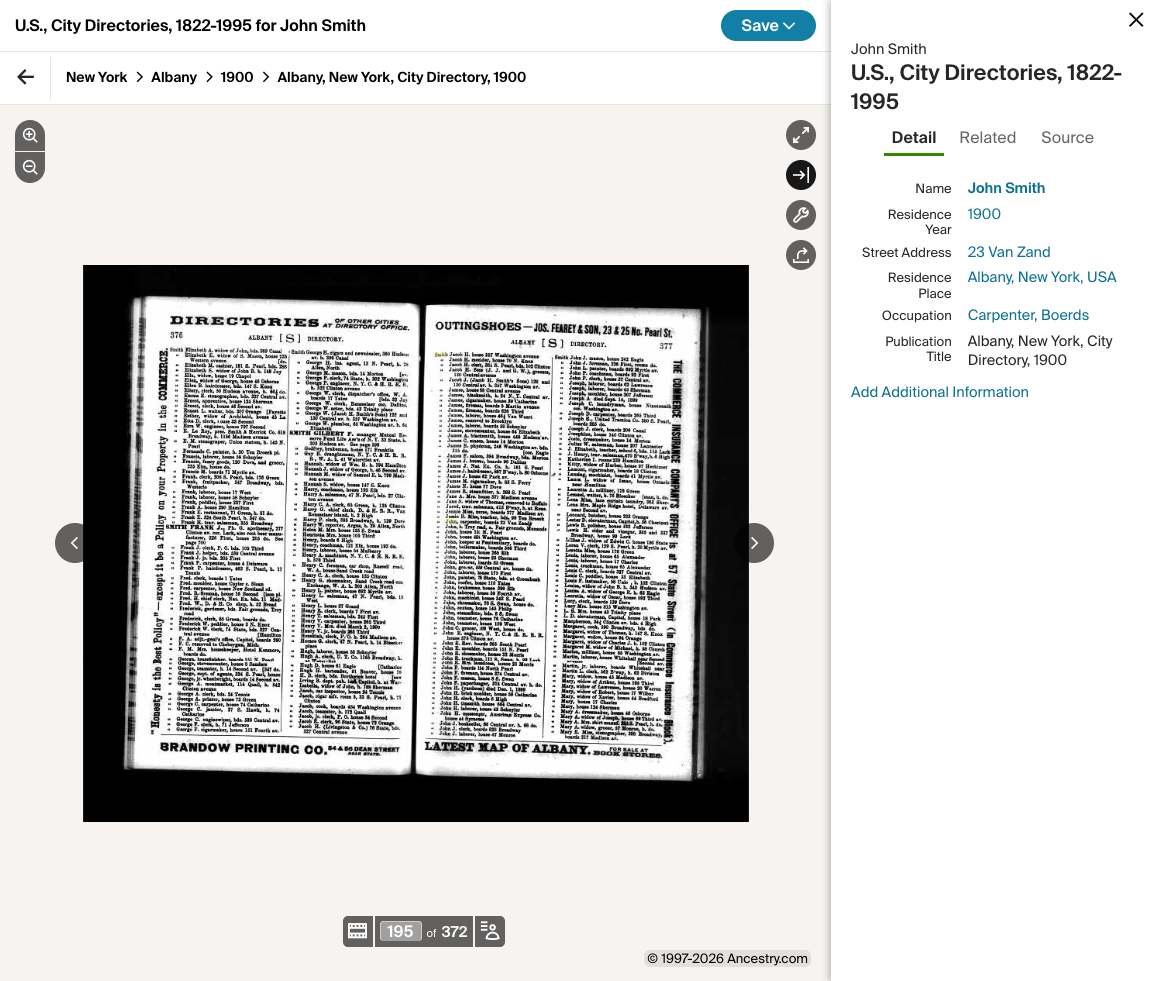
Year-by-year occupation and address for nearly every urban adult. The single largest person-level dataset on Ancestry.
Employer, occupation, and financial data for the foreign-born population—including a brand-new near-census of all non-citizens.

The richest sources on the transition from slavery to free labor markets—including wages, employers, and family structure for formerly enslaved people.
Person-level prison records spanning convict leasing through Jim Crow.
Intergenerational links, banking records, land patents, fraternal orgs, and more.